|
I am a Research Scientist at Google DeepMind working on vision and language models and other fundamental problems in Artificial Intelligence. Previously, I obtained a PhD in Informatics (Aritificial Intelligence) at the Swiss AI lab IDSIA, under the supervision of Jürgen Schmidhuber, where I worked on unsupervised/self-supervised representation learning. In particular, I am interested in learning structured (object-centric/discrete) representations with neural networks directly from raw visual input and grounding them in language. The goal is to learn object-centric representations that facilitate efficient relational reasoning, enable combinatorial (out-of-distribution) generalization of neural networks and improve their sample efficiency on the downstream task. In my PhD, I explored learning such representations in both generative and contrastive manner, as well as in an RL setup. Previously, I worked on analyzing feature extraction capabilities of convolutional neural networks via frame theory. In 2023 I was an intern at Google with Sergi Caelles and Michael Tschannen. In 2022 I was a Research Scientist Intern at DeepMind working with Alexander Lerchner, Loic Matthey, Jovana Mitrovic, Matko Bosnjak and Andre Saraiva. Previously I was a Student Researcher at Google Brain with David Ha and Yujin Tang. Prior to my PhD I received a Master's degree from ETH Zurich, and worked as a Research Engineer at uniqFEED, a spin-off company of ETH Zurich. |

|
|
My main area of interest is unsupervised representation learning of structured (object-centric) world models. Much of my research is about inferring such representations from visual observations of the physical world. |
|
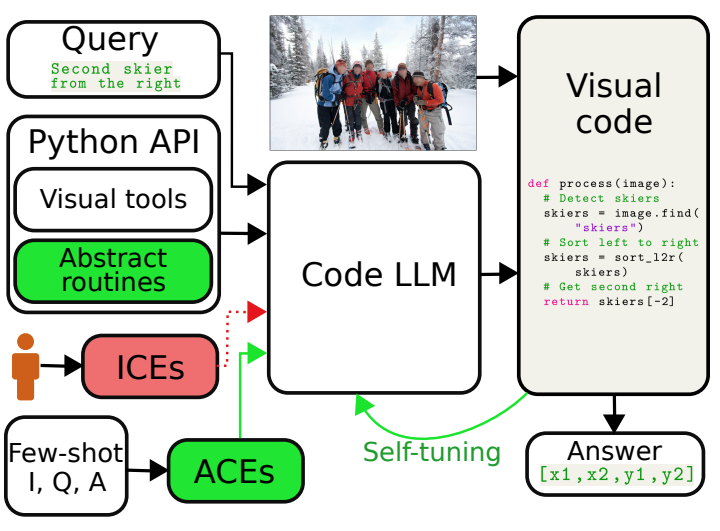
Aleksandar Stanić, Sergi Caelles, Michael Tschannen Transactions on Machine Learning Research (TMLR), 2024 Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples. |
|
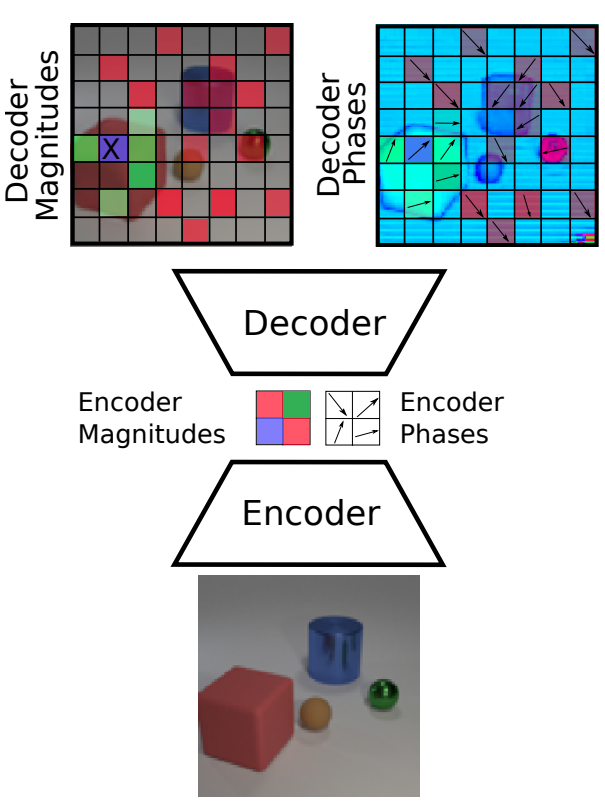
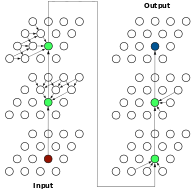
Aleksandar Stanić*, Anand Gopalakrishnan*, Kazuki Irie, Jürgen Schmidhuber *Equal contribution. Neural Information Processing Systems (NeurIPS), 2023 pdf / code Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects. |
|
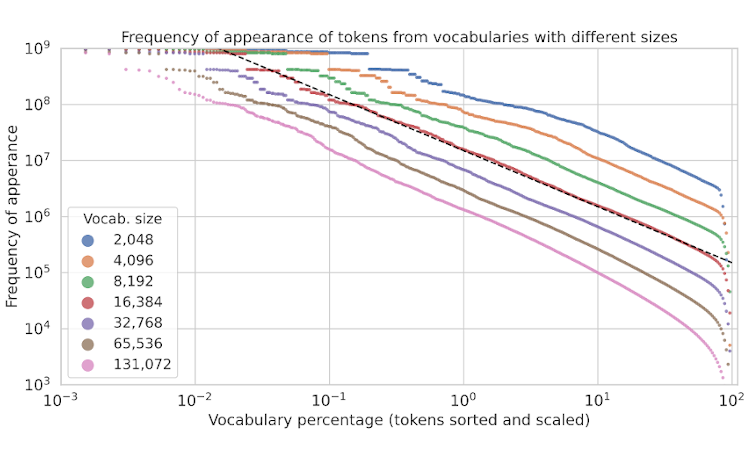
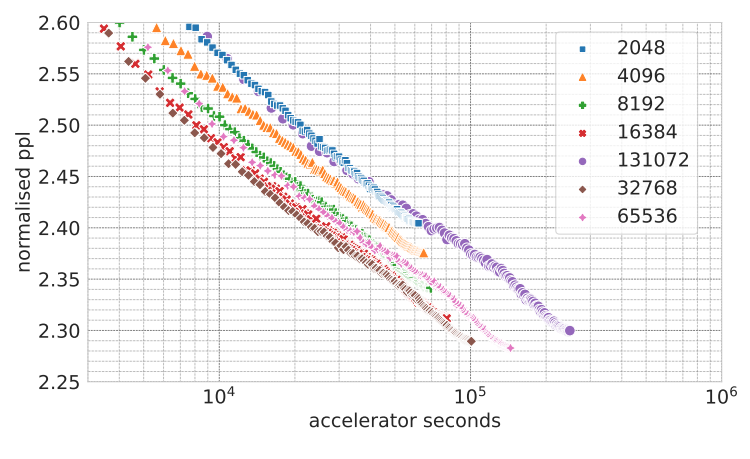
Aleksandar Stanić*, Dylan Ashley, Oleg Serikov, Louis Kirsch, Francesco Faccio, Jürgen Schmidhuber, Thomas Hofmann, Imanol Schlag* *Equal contribution. Preprint, 2023 The Languini Kitchen serves as both a research collective and codebase designed to empower researchers with limited computational resources to contribute meaningfully to the field of language modelling. We introduce an experimental protocol that enables model comparisons based on equivalent compute, measured in accelerator hours. The number of tokens on which a model is trained is defined by the model's throughput and the chosen compute class. Notably, this approach avoids constraints on critical hyperparameters which affect total parameters or floating-point operations. For evaluation, we pre-process an existing large, diverse, and high-quality dataset of books that surpasses existing academic benchmarks in quality, diversity, and document length. On it, we compare methods based on their empirical scaling trends which are estimated through experiments at various levels of compute. This work also provides two baseline models: a feed-forward model derived from the GPT-2 architecture and a recurrent model in the form of a novel LSTM with ten-fold throughput. While the GPT baseline achieves better perplexity throughout all our levels of compute, our LSTM baseline exhibits a predictable and more favourable scaling law. This is due to the improved throughput and the need for fewer training tokens to achieve the same decrease in test perplexity. Extrapolating the scaling laws leads of both models results in an intersection at roughly 50,000 accelerator hours. We hope this work can serve as the foundation for meaningful and reproducible language modelling research. |
|
Aleksandar Stanić, Yujin Tang, David Ha, Jürgen Schmidhuber IEEE Transactions on Games, 2023 Preliminary version of this work was presented at the following ICML workshops: ICML workshop on Decision Awareness in Reinforcement Learning, 2022 ICML workshop on Responsible Decision Making in Dynamic Environments, 2022 pdf / code Reinforcement learning agents must generalize beyond their training experience. Prior work has focused mostly on identical training and evaluation environments. Starting from the recently introduced Crafter benchmark, a 2D open world survival game, we introduce a new set of environments suitable for evaluating some agent's ability to generalize on previously unseen (numbers of) objects and to adapt quickly (meta-learning). We introduce CrafterOOD, a set of 15 new environments that evaluate OOD generalization. On CrafterOOD, we show that the current agents fail to generalize, whereas our novel object-centric agents achieve state-of-the-art OOD generalization while also being interpretable. We also provide critical insights of general interest for future work on Crafter through several experiments. We achieve new state-of-the-art performance on the original Crafter environment. |
|
Djordje Miladinović, Aleksandar Stanić, Stefan Bauer, Jürgen Schmidhuber, Joachim Buhmann International Conference on Learning Representations (ICLR), 2021 pdf / code Convolutional networks transformed the field of computer vision owing to their exceptional ability to identify patterns in images. However, for image generation, there exists a better alternative: spatial dependency networks (SDN). We use SDN to obtain a new state-of-the-art VAE. |
|
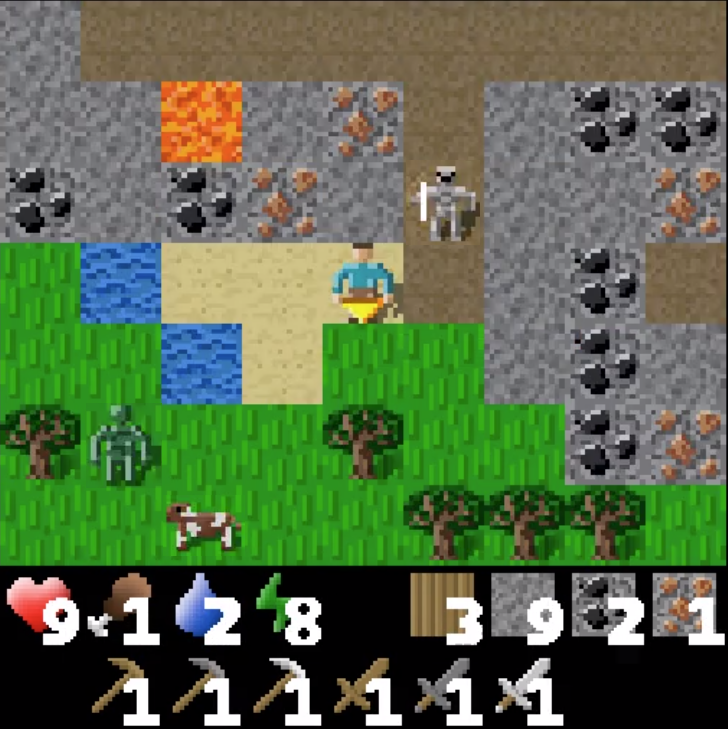
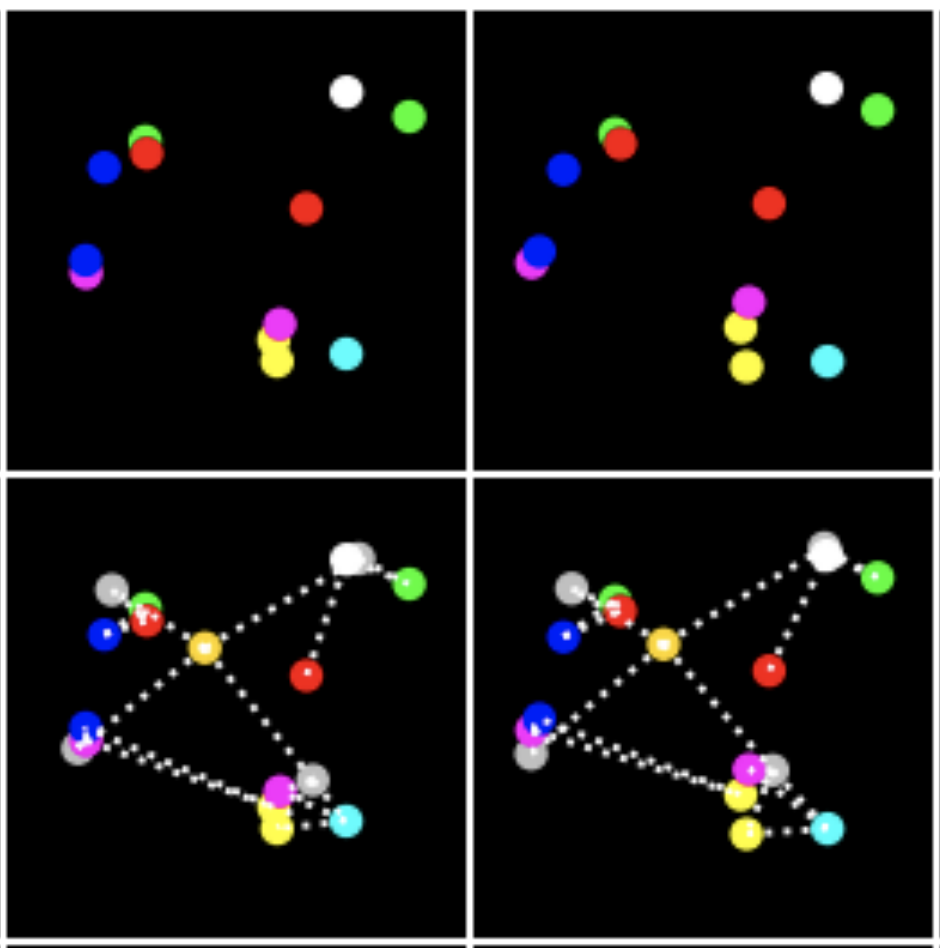
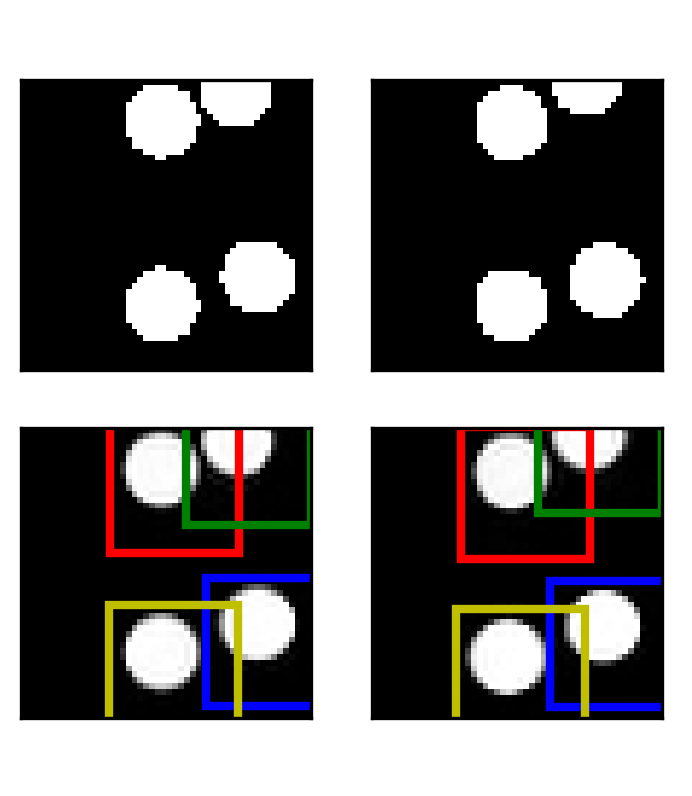
Aleksandar Stanić, Sjoerd van Steenkiste, Jürgen Schmidhuber Proceedings of the AAAI Conference on Artificial Intelligence, 2021 pdf / code / slides / poster We propose a novel approach to physical reasoning that models objects as hierarchies of parts that may locally behave separately, but also act more globally as a single whole. Unlike prior approaches, our method learns in an unsupervised fashion directly from raw visual images to discover objects, parts, and their relations. We demonstrate improvements over strong baselines at modeling synthetic and real-world physical dynamics. Preliminary version of this work was presented at the following ICML workshops:slides / video ICML Workshop on Object-Oriented Learning: Perception, Representation, and Reasoning, 2020 ICML Workshop on Bridge Between Perception and Reasoning: Graph Neural Networks & Beyond, 2020 |
|
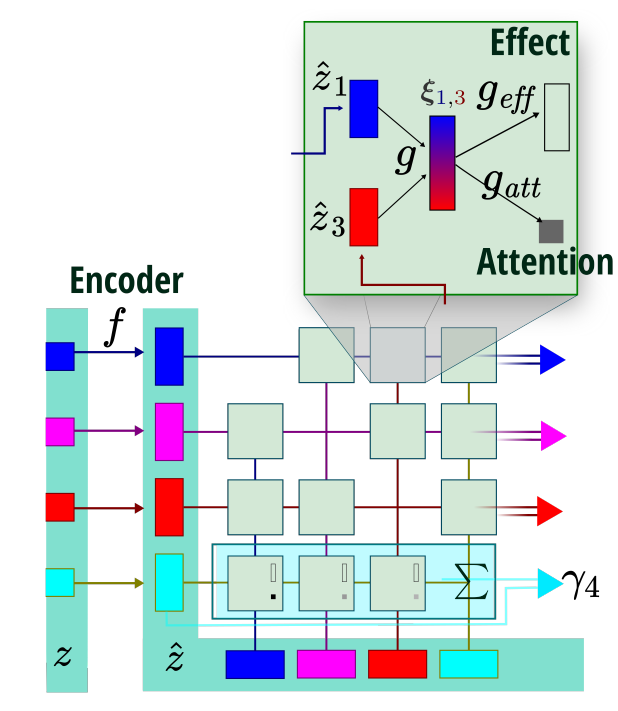
Aleksandar Stanić, Jürgen Schmidhuber NeurIPS Workshop on Perception as Generative Reasoning, 2019 NeurIPS Workshop on Graph Representation Learning, 2019 Traditional sequential multi-object attention models rely on a recurrent mechanism to infer object relations. We propose a relational extension (R-SQAIR) of one such attention model (SQAIR) by endowing it with a module with strong relational inductive bias that computes in parallel pairwise interactions between inferred objects. We demonstrate gains over sequential relational mechanisms, also in terms of combinatorial generalization. |
|
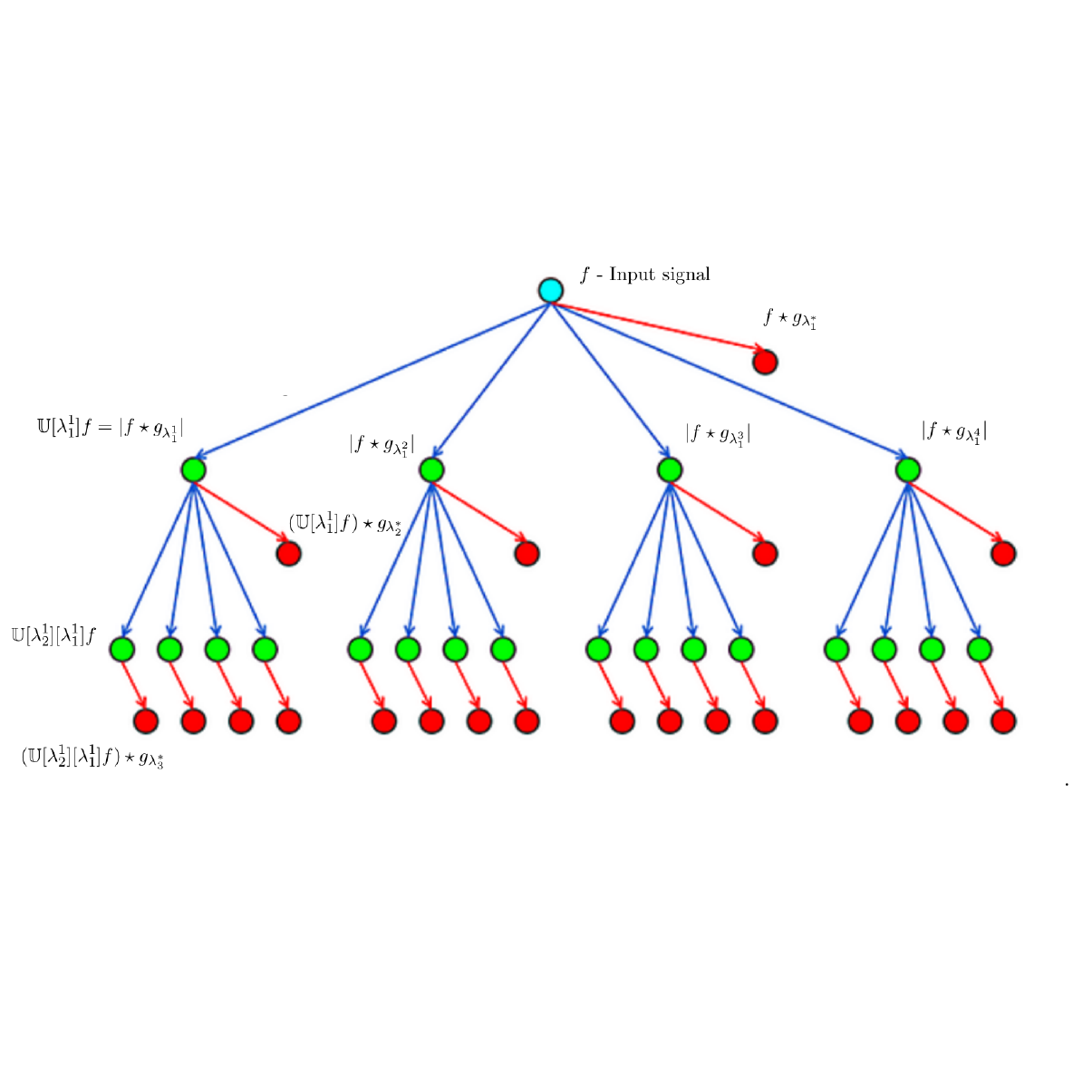
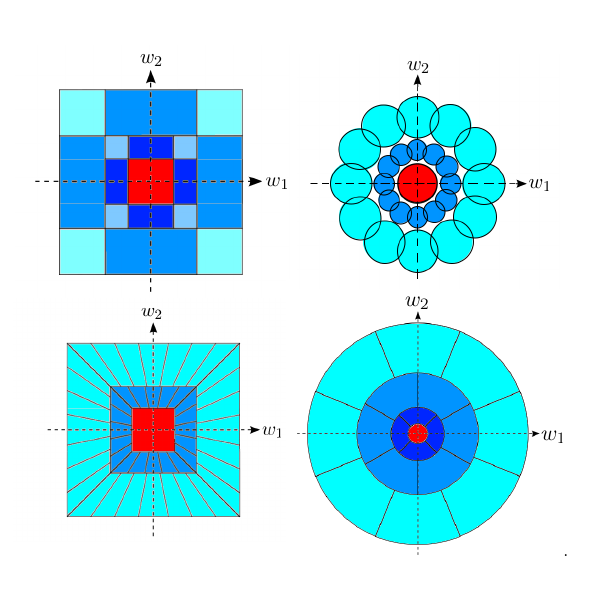
Thomas Wiatowski, Michael Tschannen, Aleksandar Stanić, Philipp Grohs, Helmut Bölcskei International Conference on Machine Learning (ICML) , 2016 pdf / code Based on frame theory, we introduce new CNN architectures, and proposes a mathematical framework for their analysis. We establish deformation and translation sensitivity results of local and global nature, and investigate how certain structural properties of the input signal are reflected in the corresponding feature vectors. Our theory applies to general filters and general Lipschitz-continuous non-linearities and pooling operators. Experiments on handwritten digit classification and facial landmark detection—including feature importance evaluation—complement the theoretical findings. |
|
Website template credits to Jon Barron. |